We’ve been talking about building a TokenSet for weeks now, it seems. We believe that having the ability to manage a Set has many advantages, and we’re hoping to build one under the Homebrew.Finance banner. My primary use case for it is being able to manage “customer funds” (e.g. friends and family) in a non-custodial way, while pooling gas costs among the entire capital pool. It’s also a way that others can follow along with my strategy as well, what TokenSets calls “social trading”.
Deploying a Set is costly, over 3.2m gas from what we’ve seen . With gas at 100 gwei and ETH close to $2000, we’re talking about $500-800 just to mint a set. That’s not something that I want to do without understanding the intricacies of managing a set, both from creating it, managing the modules and assets, and issuing/redeeming the tokens. And since there aren’t any published charts with gas costs for various operations, let’s do some testing on the Kovan testnet and see what we can come up with, shall we?
Preparation
The TokenSet docs have a list of procotol contracts, both for Mainnet and Kovan. Our first task is to execute the create function on the SetTokenCreator contract. We can do this using Etherscan, but first we need some setup tasks. First, you’ll need some Kovan tokens via this faucet, and we’ll need a list of ERC20 tokens that we can use. I started off with the Weenus ERC20 faucet tokens, but Balancer has Kovan faucets for popular tokens like WETH, DAI, USDC, WBTC and others.
Now I originally did this test deployment using the Etherscan write interaction, but I’ve since discovered the wonderful seth , a “Metamask for the command line. It’s much easier to use than writing a web3 script or using the Etherscan webpage. After a couple minutes setting it up I was able to interact with Kovan using my dev Ethereum address. The hardest part was exporting and saving the private key from Metamask to a JSON keystore file using the MEW CX Chrome plugin. I also put the password in a text file, then configured the .sethrc file to unlock the account and use it via my Infura project URL. Needless to say, I don’t use this account for anything of value, and don’t recommend you do this with production keys.
Creating the set
I literally spent hours trying to figure out how to call this transaction to create the set. Most of my time was spent trying to get things working on Etherscan, but I wasn’t quite sure how to call the contract arguments. First, let’s take a look at the function call parameters. Per the documentation:
function create(
address[] memory _components,
int256[] memory _units,
address[] memory _modules,
address _manager,
string memory _name,
string memory _symbol
)
external
returns (address)Most of this is pretty easy to understand: _components is an array of the tokens in the set, _modules are the components of the Set Protocol that the set needs to operate. _manager, _name and _symbol don’t need any explanation. But what about _units? The docs define it as “the notional amount of each component in the starting allocation”, but the word notional doesn’t really have a definition that makes sense to me in a programming context.
So let’s take a look at the SetProtocol UI to see how this works.
To start with, let’s create a set with one-hundred percent allocation of USDC. Let’s set the Set price to one dollar. I’m calling it the “One Dollar Set”, and the token to 1USD. We can grab the hex data from the Metamask confirmation prompt, and throw it in this Ethereum input data decoder. For this contract, you can get the ABI from the Etherscan page, but for unverified ones you may need to compile it yourself.
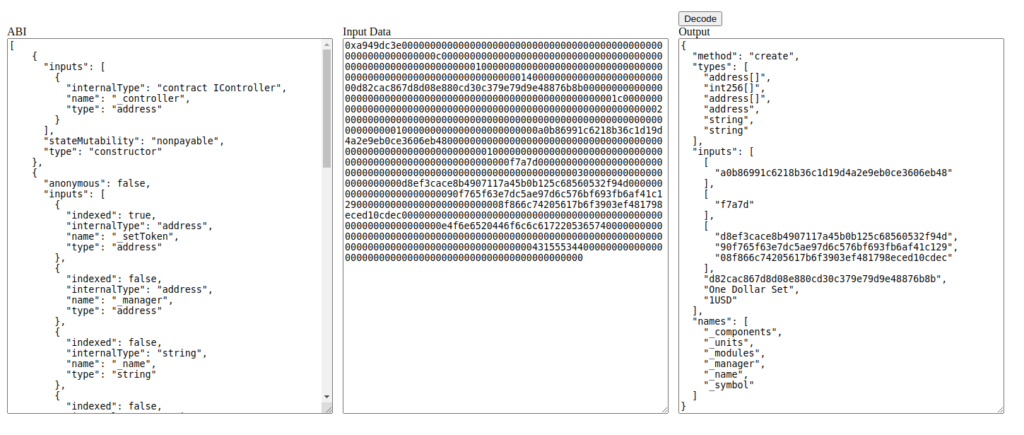
Here’s how we can do that programmatically using seth:
$ export CREATE_SIGNATURE="create(address[],int256[],address[],address,string,string)"
$ export ONE_USD="0xa949dc3e00000000000000000000000000000000000000000000000000000000000000c000000000000000000000000000000000000000000000000000000000000001000000000000000000000000000000000000000000000000000000000000000140000000000000000000000000d82cac867d8d08e880cd30c379e79d9e48876b8b00000000000000000000000000000000000000000000000000000000000001c000000000000000000000000000000000000000000000000000000000000002000000000000000000000000000000000000000000000000000000000000000001000000000000000000000000a0b86991c6218b36c1d19d4a2e9eb0ce3606eb48000000000000000000000000000000000000000000000000000000000000000100000000000000000000000000000000000000000000000000000000000f7a7d0000000000000000000000000000000000000000000000000000000000000003000000000000000000000000d8ef3cace8b4907117a45b0b125c68560532f94d00000000000000000000000090f765f63e7dc5ae97d6c576bf693fb6af41c12900000000000000000000000008f866c74205617b6f3903ef481798eced10cdec000000000000000000000000000000000000000000000000000000000000000e4f6e6520446f6c6c61722053657400000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000043155534400000000000000000000000000000000000000000000000000000000"
0xA0b86991c6218b36c1d19D4a2e9Eb0cE3606eB48 // USDC token address
1014397 // 'nominal' amount
0xd8EF3cACe8b4907117a45B0b125c68560532F94D,0x90F765F63E7DC5aE97d6c576BF693FB6AF41C129,0x08f866c74205617B6F3903EF481798EcED10cDEC // tokenset modules
0xd82Cac867d8D08E880Cd30C379e79d9e48876b8b // my dev address
One Dollar Set // name
1USD //symbol
So let’s take a look at this nominal amount. The documentation doesn’t really explain it, but I did some experimenting to see what the values come out to.
| Allocation | Starting Price | Hex | Decimal |
| 100% USDC | $1 | f4b2e | 1,000,286 |
| $10 | 98efce | 10,022,862 | |
| $100 | 5f5e100 | 100,000,000 | |
| $1000 | 3b9aca00 | 1,000,000,000 | |
| 50/50 USDC/USDT | $1 | 7a120 | 500,000 |
| $10 | 4c4b40 | 5,000,000 |
The single asset one and ten dollar prices seem to be anomalies, I’m guessing due to precision errors or something. Let’s look at a more realistic mix of a Set with an allocation between wBTC, wETH, USDC and DPI token:
| Starting Price | Token | Hex | Decimal |
| $10 | wBTC | 14c6 | 5318 |
| wETH | 524a299c0f0f1 | 1,447,655,666,413,809 | |
| USDC | 263447 | 2503751 | |
| DPI | 1658cfe35c0f54 | 6,290,099,383,570,260 | |
| $100 | wBTC | cfb8 | 53,176 |
| wETH | 336757534418dd | 14,468,848,569,030,877 | |
| USDC | 17dd051 | 25,022,545 | |
| DPI | df5708b80c3c0c | 62,864,614,765,640,716 |
So what we’ve determined here is that the decimal numbers correspond to the fractional portion of the various tokens in USD. For example, the value 5318 for BTC corresponds to 0.00005318 BTC, with BTC at $48k, corresponds to approximately $2.50 worth of BTC.
It seems that the TokenSet UI uses their an oracle system to determine these weights, based on the allocation and opening price given. One could compute these manually, or copy the values from the TokenSet UI as I did here. Just remember that the nominal value of each token you have in your set will determine the USD price. For practical reasons regarding issuance, you might want to consider starting with a single component, such as USDC, wETH or wBTC.
Deploying our set
The TokenSet UI creates new Sets with the following modules: basic issuance, trade module, and streaming fee. The basic issuance requires issuers to have the correct ratio of the Set’s inputs, and also requires approval for each spend. It is very expensive to do this. For this reason we want to use the NAV module, which allows users to deposit tokens using a single asset. However, the NAV module only supports issuance with assets that are supported using SetProtocol’s on-chain oracles, and these are limited. (More on this in our next post.)
Using Etherscan
One of the big problems I had trying to pass these parameters in via Etherscan was how to encode them the values. Eventually, with some help from a Set team member, I figured out that arrays of addresses, such as those for the component assets and modules, need to be enclosed in quotes, without the “0x” prefix intact. The int256 array for the component amounts need to be in hex form, with the 0x prefix intact. Here’s how it looks on Etherscan:
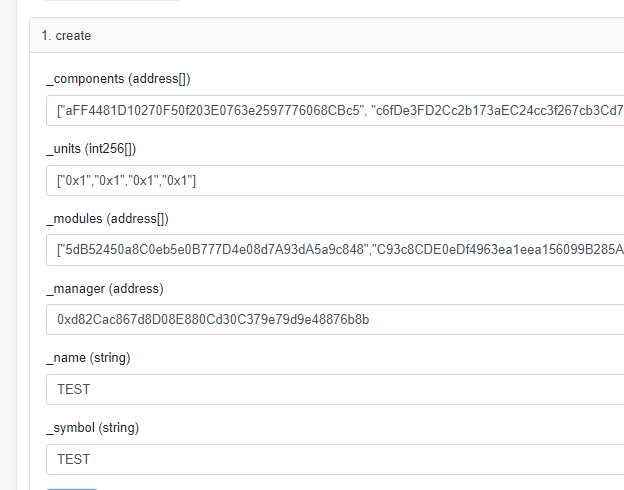
You can see the result of this transaction on Etherscan. The total gas used was 3,308,683. That’s about 0.13ETH at 40 gwei, but I doubt I’ll be able to get a tx through at that price given recent prices. Earlier testing on the UI actually showed a price around three thousand dollars last night when gas was closer to 400 gwei. I believe that Set creation is not a time sensitive process like trading on Uniswap, so we can try to sneak by with a lower cost gas fee if we want to.
Using SETH
export ETH_FROM=$(seth accounts | head -n1 | awk '{ print $1 }')
export ZERO=0x0000000000000000000000000000000000000000000000000000000000000000
export WEENUS=0xaFF4481D10270F50f203E0763e2597776068CBc5
export YEENUS=0xc6fDe3FD2Cc2b173aEC24cc3f267cb3Cd78a26B7
export XEENUS=0x022E292b44B5a146F2e8ee36Ff44D3dd863C915c
export ZEENUS=0x1f9061B953bBa0E36BF50F21876132DcF276fC6e
export SET_TOKEN_CREATOR=0xB24F7367ee8efcB5EAbe4491B42fA222EC68d411
export NAV_ISSUANCE_MODULE=0x5dB52450a8C0eb5e0B777D4e08d7A93dA5a9c848
export STREAMING_FEE_MODULE=0xE038E59DEEC8657d105B6a3Fb5040b3a6189Dd51
export TRADE_MODULE=0xC93c8CDE0eDf4963ea1eea156099B285A945210a
export CREATE_SIGNATURE="create(address[],int256[],address[],address,string,string)"
export COMPONENTS=[$WEENUS,$XEENUS,$YEENUS,$ZEENUS]
export UNITS=["0x1","0x1","0x1","0x1"]
export MODULES=[$NAV_ISSUANCE_MODULE,$STREAMING_FEE_MODULE,$TRADE_MODULE]
export NAME='"TEST"'
export SYMBOL='"TEST24"'
seth send $SET_TOKEN_CREATOR $CREATE_SIGNATURE $COMPONENTS $UNITS $MODULES $ETH_FROM $NAME $SYMBOL --gas=4000000
seth-send: Published transaction with 772 bytes of calldata.
seth-send: 0xc12a5402ff37e114d8951fef756ab6985e6387b0e5d74e8c6ee5b83913077a86
seth-send: Waiting for transaction receipt...........
seth-send: Transaction included in block 23634932.Here, we are using export to create bash variables to make our code more readable. We set our own address $ETH_FROM, as well as the zero address for use later, then create vars for the components in our Set, WEENUS et al, the Set creator contract, as well as the modules that we’ll have in our set. We provide the signature for the create function, then bundle our parameters together before sending the transaction with four million gas.
Note that we could use the seth estimate function to get a fairly accurate measure of the actual gas needed:
seth estimate $SET_TOKEN_CREATOR $CREATE_SIGNATURE $COMPONENTS $UNITS $MODULES $ETH_FROM $NAME $SYMBOL --gas=4000000
3308707
This is exactly how much gas was used by our actual Set creation transaction.
Using web3
Jacob Abiola was gracious enough to create this SetTokenCreator-boilerplate repo for me, showing how to create a Set using a Javascript file and web3 via Infura and Metamask.
Where’s my Set?
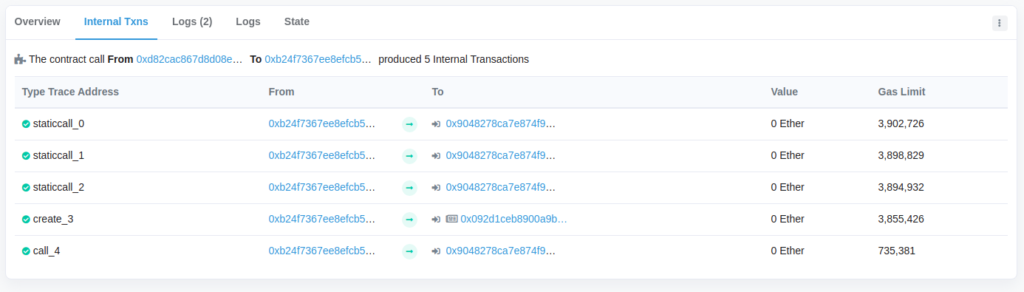
If you look at the internal transactions for the set creation call that we just minted, you’ll see the create call is made on a brand new contract. The one below, starting with 0x902d1ce… is our new $TEST24 token on Kovan.
On our next post, we’ll take a look at some of the challenges around issuing tokens. The basic and NAV issuance modules are very misunderstood, and we’ve had many requests from people asking how we’re dealing with it with the $MUG token.





