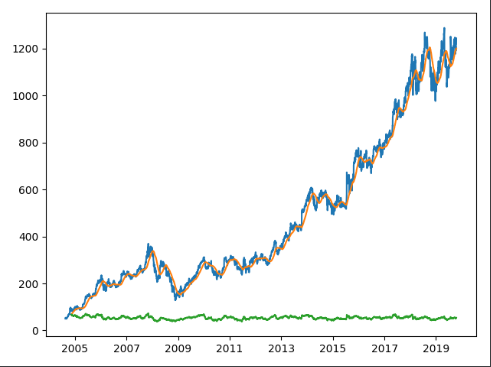
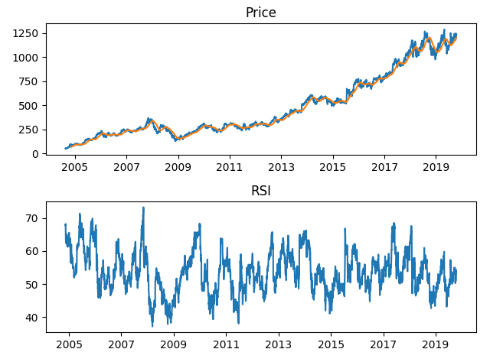
In our previous posts (part 1, part 2) we showed how to get historical stock data from the Alpha Vantage API, use Pickle to cache it, and how prep it in Pandas. Now we are ready to throw it in Prophet!
So, after loading our main.py file, we get ticker data by passing the stock symbol to our get_symbol function, which will check the cache and get daily data going back as far as is available via AlphaVantage.
>>> symbol = "ARKK"
>>> ticker = get_symbol(symbol)
./cache/ARKK_2019_10_19.pickle not found
{'1. Information': 'Daily Prices (open, high, low, close) and Volumes', '2. Symbol': 'ARKK', '3. Last Refreshed': '2019-10-18', '4. Output Size': 'Full size', '5. Time Zone': 'US/Eastern'}
{'1: Symbol': 'ARKK', '2: Indicator': 'Simple Moving Average (SMA)', '3: Last Refreshed': '2019-10-18', '4: Interval': 'daily', '5: Time Period': 60, '6: Series Type': 'close', '7: Time Zone': 'US/Eastern'}
{'1: Symbol': 'ARKK', '2: Indicator': 'Relative Strength Index (RSI)', '3: Last Refreshed': '2019-10-18', '4: Interval': 'daily', '5: Time Period': 60, '6: Series Type': 'close', '7: Time Zone': 'US/Eastern Time'}
./cache/ARKK_2019_10_19.pickle savedRunning Prophet
Now we’re not going to do anything here with the original code other than wrap it in a function that we can call again later. Our alpha_df_to_prophet_df() function renames our datetime index and close price series data columns to the columns that Prophet expects. You can follow the original Medium post for an explanation of what’s going on; we just want the fitted history and forecast dataframes in our return statement.
def prophet(ticker, fcast_time=360):
ticker = alpha_df_to_prophet_df(ticker)
df_prophet = Prophet(changepoint_prior_scale=0.15, daily_seasonality=True)
df_prophet.fit(ticker)
fcast_time = fcast_time
df_forecast = df_prophet.make_future_dataframe(periods=fcast_time, freq='D')
df_forecast = df_prophet.predict(df_forecast)
return df_prophet, df_forecast
>>> df_prophet, df_forecast = prophet(ticker)
Initial log joint probability = -11.1039
Iter log prob ||dx|| ||grad|| alpha alpha0 # evals Notes
99 3671.96 0.11449 1846.88 1 1 120
...
3510 3840.64 3.79916e-06 20.3995 7.815e-08 0.001 4818 LS failed, Hessian reset
3534 3840.64 1.38592e-06 16.2122 1 1 4851
Optimization terminated normally:
Convergence detected: relative gradient magnitude is below toleranceThe whole process runs within a minute. Even twenty years of Google daily data can be processed quickly.
The last thing we want to do is concat the forecast data back to the original ticker data and Pickle it back to our file system. We rename our index back ‘date’ as it was before we modified it, then join it to the original Alpha Vantage data.
def concat(ticker, df_forecast):
df = df_forecast.rename(columns={'ds': 'date'}).set_index('date')[['trend', 'yhat_lower', 'yhat_upper', 'yhat']]
frames = [ticker, df]
result = pd.concat(frames, axis=1)
return resultSeeing the results
Since these are Pandas dataframes, we can use matplotlib to see the results, and Prophet also includes Plotly support. But as someone who looks at live charts in TradingView throughout the day, I’d like something more responsive. So we loaded the Bokeh library and created the following function to match.
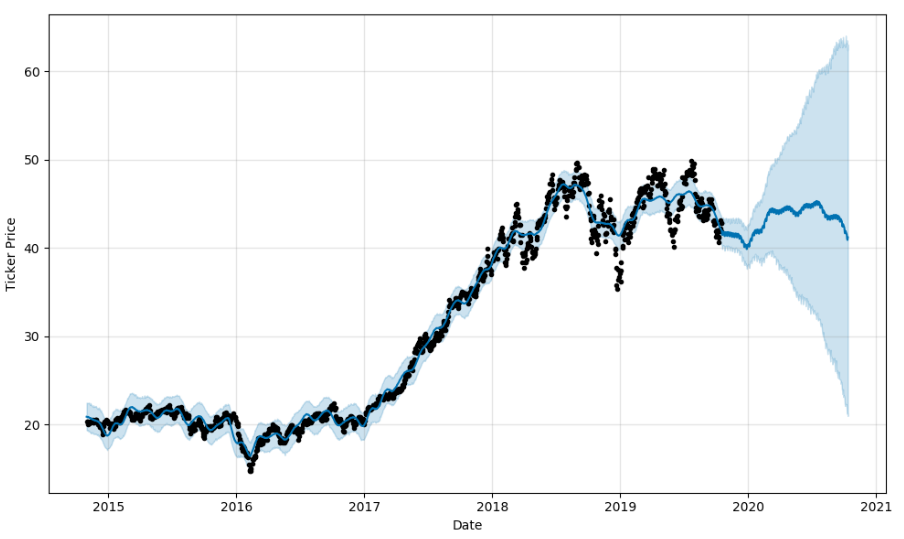
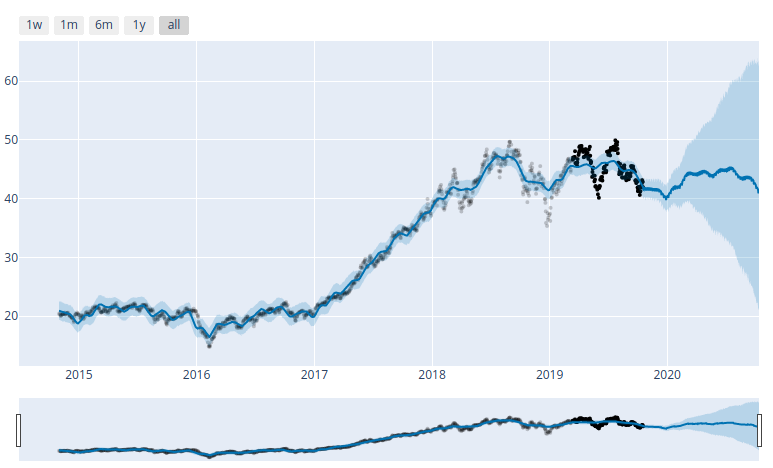
def prophet_bokeh(df_prophet, df_forecast):
p = figure(x_axis_type='datetime')
p.varea(y1='yhat_lower', y2='yhat_upper', x='ds', color='#0072B2', source=df_forecast, fill_alpha=0.2)
p.line(df_prophet.history['ds'].dt.to_pydatetime(), df_prophet.history['y'], legend="History", line_color="black")
p.line(df_forecast.ds, df_forecast.yhat, legend="Forecast", line_color='#0072B2')
save(p)
>>> output_file("./charts/{}.html".format(symbol), title=symbol)
>>> prophet_bokeh(df_prophet, df_forecast)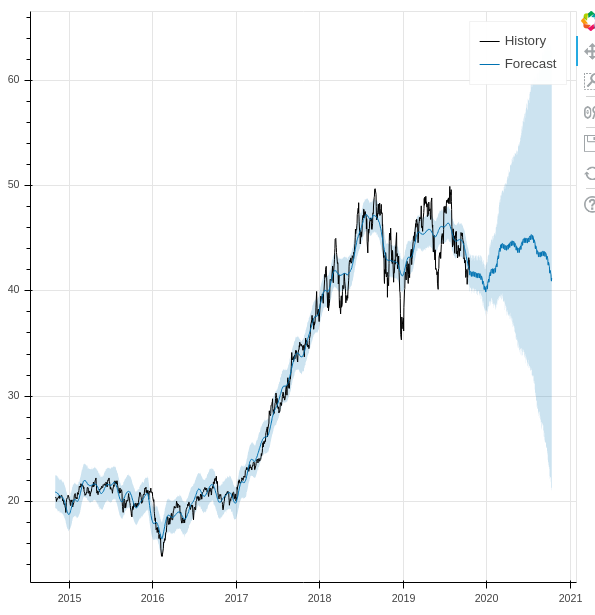
Putting it all together
Our ultimate goal here is to be able to process large batches of stocks, downloading the data from AV and processing it in Prophet in one go. For our initial run, we decided to start with the bundle of stocks in the ARK Innovation ETF. So we copied the holdings into a Python list, and created a couple of functions. One to process an individual stock, an another to process the list. Everything in the first function should be familiar except for two things. One, we added a check for the ‘yhat’ column to make sure that we didn’t inadvertently reprocess any individual stocks while we were debugging. We also refactored get_filename, which just adds the stock ticker plus today’s date to a string. It’s used in get_symbol during the Alpha Vantage call, as well as here when we save the Prophet-ized data back to the cache.
def process(symbol):
ticker = get_symbol(symbol)
if 'yhat' in ticker:
print("DF exists, exiting")
return
df_prophet, df_forecast = prophet(ticker)
output_file("./charts/{}.html".format(symbol), title=symbol)
prophet_bokeh(df_prophet, df_forecast)
result = concat(ticker, df_forecast)
file = get_filename(symbol, CACHE_DIR) + '.pickle'
pickle.dump(result, open(file, "wb"))
returnFinally, our process_list function. We had a bit of a wrinkle at first. Since we’re using the free AlphaVantage API, we’re limited to 5 API calls per minute. Now since we’re making three in each get_symbol() call we get an exception if we process the loop more than once in sixty seconds. Now I could have just gotten rid of the SMA and RSI calls, ultimately decided just to calculate the duration of each loop and just sleep until the minute was up. Obviously not the most elegant solution, but it works.
def process_list(symbol_list):
for symbol in symbol_list:
start = time.time()
process(symbol)
end = time.time()
elapsed = end - start
print ("Finished processing {} in {}".format(symbol, elapsed))
if elapsed > 60:
continue
elif elapsed < 1:
continue
else:
print('Waiting...')
time.sleep(60 - elapsed)
continueSo from there we just pass our list of ARKK stocks, go for a bio-break, and when we come back we’ve got a cache of Pickled Pandas data and Bokeh plots for about thirty stocks.
Where do we go now
Now I’m not putting too much faith into the results of the Prophet data, we didn’t do any customizations, and we just wanted to see what we can do with it. In the days since I started writing up this series, I’ve been thinking about ways to calculate the winners of the plots via a function call. So far I’ve come up with this discount function, that determines the discount of the current price of an asset relative to Prophet’s yhat prediction band.
Continuing with ARKK:
def calculate_discount(current, minimum, maximum):
return (current - minimum) * 100 / (maximum - minimum)
>>> result['discount'] = calculate_discount(result['4. close'], result['yhat_lower'], result['yhat_upper'])
>>> result.loc['20191016']
1. open 42.990000
2. high 43.080000
3. low 42.694000
4. close 42.800000
5. volume 188400.000000
SMA 44.409800
RSI 47.424600
trend 41.344573
yhat_lower 40.632873
yhat_upper 43.647911
yhat 42.122355
discount 71.877276
Name: 2019-10-16 00:00:00, dtype: float64A negative number for the discount indicates that the current price is below the prediction band, and may be a buy. Likewise, anything over 100 is above the prediction range and is overpriced, according to the model. We did ultimately pick two out of the ARKK holding that were well below the prediction range and showed a long term forecast, and we’ve started scaling in modestly while we see how things play out.
If we were more cautious, we’d do more backtesting, running limited time slices through Prophet and comparing forecast accuracy against the historical data. Additionally, we’d like to figure out a way to weigh our discount calculation against the accuracy projections.
There’s much more to to explore off of the original Medium post. We haven’t even gotten into integrating Alpha Vantage’s cryptoasset calls, nor have we done any of the validation and performance metrics that are part of the tutorial. It’s likely a part 4 and 5 of this series could follow. Ultimately though, our interest is to get into actual machine learning models such as TensorFlow and see what we can come up with there. While we understand the danger or placing too much weight into trained models, I do think that there may be value to using these frameworks as screeners. Coupled with the value averaging algorithm that we discussed here previously, we may have a good strategy for long-term investing. And anything that I can quantify and remove the emotional factor from is good as well.
I’ve learned so much doing this small project. I’m not sure how much more we’ll do with Prophet per se, but the Alpha Vantage API is very useful, and I’m guessing that I’ll be doing a lot more with Bokeh in the future. During the last week I’ve also discovered a new Python project that aims to provide a unified framework for coupling various equity and crypto exchange APIs with pluggable ML components, and use them to execute various trading strategies. Watch this space for discussion on that soon.